FAQ/Izenda Caching Lifecycle

This documentation is for the legacy Izenda 6 product. Documentation for the new Izenda 7 product can be found at https://www.izenda.com/docs/
Izenda Caching Lifecycle
There is no single life-cycle of caching in Izenda. There are several caches which act simultaneously and independently on each other, the 'cycle' will always be different depending on your given Izenda usage scenario.
However, each cache has an individual life-cycle that exists and is rather strict.
Below is a description of the caches existing in Izenda along with a brief life-cycle for each of them.
DatabaseSchema-related caches in Driver class.
DatabaseSchema generation consists of two actions:
"Internal": Constructs the schema from the scratch
"External": Wrapper which tries to get somewhere ready schema object. If it fails, it calls "Internal" one.
There are two independent caches - one for each action.
When DatabaseSchema getter is called, "external" action takes place:
1) Driver identifies storage for schema which should be used:
a) If CacheSchema disabled, then it will be Request storage (lives only during processing current request)
b) If CacheSchema enabled, then:
1) If PerUserCaching disabled, then it will be Session (individual for every user)
2) If PerUserCaching is enabled, then it will be Application (shared across users)
2) Now when Driver knows which storage should be used, it checks if schema object exists there
q) If schema object is found in storage, Driver just returns it
b) If schema was not found, Driver calls ExtractSchema
c) When ExtractSchema returns schema object, Driver puts it to storage, and also returns it.
As you can see, it can either return the existing schema object from some cache, or can decide to call "Internal" action represented by method ExtractSchema.
When ExtractSchema is called, it does following:
1) Checks if there is raw schema data on disk (files with names of tables/columns existing in database):
a) If raw schema data is found on disk it just loads it
b) If raw schema data was not found on disk:
1) It pulls raw schema data from database
2) Saves this raw schema data to disk, and does further work with it
2) It constructs schema object from the obtained raw schema data, and returns it
So here is second cache which stores raw schema data on disk. It allows to skip slow pulling raw schema data from database.
This cache works always, for every Driver.DatabaseSchema getter call, from the application start to the application finish
Query-related caches in Driver class.
This one is very simple.
When GetDataSet executes (it accepts IDbCommand and returns DataSet object), internally it does following:
1) If CacheQueries disabled, it executes sql command and returns result
2) If CacheQueries enabled, it:
a) Checks if there is a DataSet object corresponding to the given IDbCommand in Application cache
b) If DataSet is found in cache, it just returns it
c) If DataSet was not found, it executes sql command, puts resulting DataSet to Application cache, and also returns it
This cache, as you can see, acts completely independently on all other caches, for example independently on mentioned above schema-related cache. It allows to avoid repeating execution of slow SQL commands, and its effect is especially noticeable for example when you have reportset with very slow query to obtain results for rendering results.
This cache works always, for every Driver.GetDataSet call, from the application start to the application finish
Caches for ReportList
Another completely stand-alone, independent on other things cache.
It stores objects used to render ReportList for existing reports. For every reportSet it keeps 3 objects: ReportSet XML definition, thumbnail (if exists), and html Form (if exists).
Logics of its work is rather complex in small details, but in general it does following.
For every AdHocConfig.ListReports() call:
1) If UseCachedFilteredLists is disabled, it just pulls whole reportlist-related data from the scratch from the storage, and returns it
2) If UseCachedFilteredLists is enabled, it:
a) Pulls from storage XMLs, Forms, and thumbnails for reports modified after %moment_of_previous_call%
b) Sets %moment_of_previous_call% to current moment of time
c) Adds pulled XMLs/Forms/thumbnails to the storage of reportlist-related objects in Session
d) Returns all contents of reportlist-related objects in session
So when it's enabled, when ListReports is called, this cache instead of pulling all data from the scratch from disk/DB, pulls only changes since latest call, then incorporates those changes into the reportlist-related data from previous call which is kept in Session, and returns the updated reportlist-related data.
Caches for reports
Another completely stand-alone, independent cache.
It stores deserialized ReportSet objects.
This cache is also rather simple.
When AdHocConfig.LoadReportSetInternal() is called (it accepts reportInfo and returns ReportSet), it tries to pick ReportSet from Application using passed ReportInfo.
If ReportSet is not found, then it will load XML definition and deserialize it. Then put result to Application, and also return it.
While if ReportSet will be found in Application - it will return it, skipping loading and deserialization of XML.
Note that if given cache misses ReportSet in Application and loads XML for deserialization - then it will be a time for mentioned above "Cache for ReportList" - which keeps ReportSet XMLs in memory along with Forms/thumbnails.
So given cache is some kind of "upper-level" cache according to the "cache for ReportList"
So as you can see, though these caches are completely independent by the functionality and can be independently enabled/disabled, they are "nested" - if given cache fails, then there is a chance for "Cache for ReportList" to fire during the XML loading.
Html Output cache
Very complicated internally, but rather simple in its external appearance cache.
It "intercepts" reportSet rendering in the moment before SQL generation, and verifies if there is already rendered HTML result for the given reportSet/situation in the cache. If it "decides" that it has the readt rendered HTML result - it cancels whole following reportSet processing (SQL generation, execution, HTML rendering) and jumps right to the point where HTML should be used (returning to browser for example) providing there the HTML from storage.
If ready HTML was not found in storage, it allows full necessary reportSet processing, and in the end of it puts to storage the prepared HTML result for further usage in case if the same reportSet will be required to be rendered in same circumstances.
Images/CSS/JS cache
This cache is mainly implemented in ResponseServer. It caches images/css/js files queried by user (browser), if StoreImagesToCache is enabled.
Caching with multiple users
Izenda's schema caching system works as following:
1) There is a persistent cache on disk.
2) There is an application-wide schema object in static memory in server process.
Both 1 and 2 above are shared across site users.
3) When VisibleDatasources gets some array of names assigned, the following occurs:
a) Izenda runs through the assigned array of datasource names, and throws away all those which are already present in schema object in static memory (thus are already available in system for reporting purposes).
b) The remaining datasource names must be added to the in-memory schema object. Izenda runs through these remaining datasources, and tries to find schema data for each of them in disk cache.
If schema data is found in disk cache for a given datasource, then it gets filled with that data, added to in-memory schema object (becoming available in system for reporting), and discarded from the array of assigned datasources.
c) The remaining datasources are not present in schema object in-memory, and also don't have schema data in disk cache, so Izenda must pull their data from DB. Izenda generates a temporary table with names of these datasources (starting with "#datasources_"), and runs several SQL queries to pull schema data for them from DB. Then Izenda fills the in-memory schema object with this data and also stores this data to schema cache.
So if in the future after server restart, some of these datasources are assigned to VisibleDatasources, Izenda will take their data from disk cache without hitting DB.
Additional Information
There are a bunch of other tiny local caches within Izenda, which don't interact with users/developers directly, and are not regulated by any settings/conditions. Actually they often represent just a private non-persistent variable or collection in some class, so aren't worth mentioning in detail.
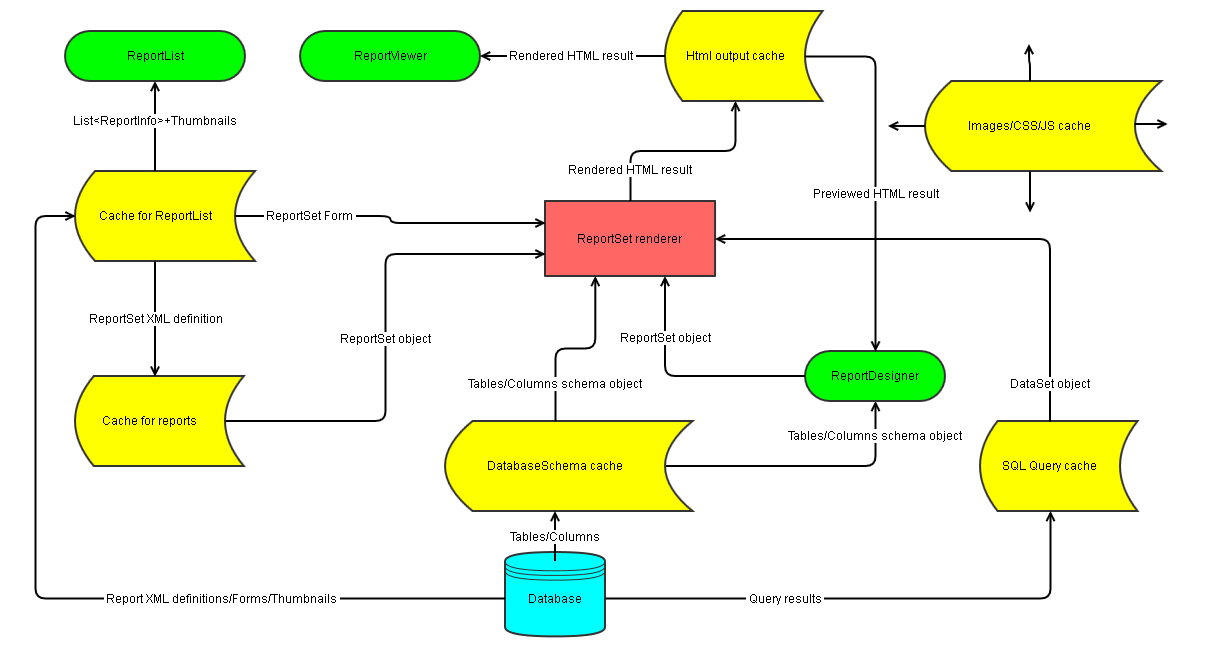
While 6 most important and global caches are described above. We have also tried to draw some a kind of schema which shows which data goes between those 6 caches, DB, and the main Izenda pages (ReportList/ReportViewer/ReportDesigner).
Describing the diagram
When the data is requested from the given cache by the successive block through the arrow "outgoing" from cache figure, the cache first tries to find necessary data inside itself. If it finds data - it returns it to the successive block through "outgoing" arrow and that successive block continues its work.
If cache doesn't find data - then it requests this data through the arrow "incoming" into its figure from the previous block. When previous block produces this data, cache stores it and also sends it to the successive block through "outgoing" arrow.
So there is no any kind of "full cycle of data flow" through all these arrows each time when user does something. Instead, each of these caches work like buffer/accumulator/floodgate - each of them acts independently in the data flow into which it is inserted, either returning previously cached data with prevention of "deeper" blocks work. Or if data is not cached yet - then it passes execution to the "deeper" blocks of code which should produce necessary data.